
“Elizondo” es un apellido que muchas personas en los Estados Unidos batallan para pronunciar correctamente. En la escuela, cuando yo era joven, escuché todas los días durante la asistencia, “Sierra EliZondo”, y a veces “Sierra EliSondo”. Siempre supe que el primero estaba equivocado, pero no sabía si la persona que decía mal mi nombre lo sabía también. Viviendo en Tejas, siempre oía una mezcla, incluso de la gente que sabe español. Aunque la gente bilingüe tenía una pronunciación menos áspera que los angloparlantes, pronunciaban ellos más la “z” que los hispanohablantes monolingües.
Hay muchas personas en los Estados Unidos que son bilingües, y una gran población de ellas vive en Tejas, especialmente aquellas con herencia mexicana. De acuerdo al Pew Research Center, en 2021, vivían en los Estados Unidos unos 37.2 millones de hispanos con herencia mexicana (Moslimani et al., 2023). Históricamente sabemos que el dialecto mexicano, la base del español hablado en Tejas, es muy conservador, lo que significa que generalmente se pronuncia como se escribe y no modifica mucho las palabras al hablar, en comparación con el dialecto puertorriqueño, por ejemplo (Morgan, 2010). Se pueden observar diferencias claras entre regiones hispanos, como la interdental típica de España o la aspiración y la elisión del Caribe, América Central y las costas de América. Por ejemplo, en la palabra “zapatos”, las ocurrencias del sonido /s/ pueden pronunciarse con la interdental [θa.’pa.tos] en Madrid, con la elision [sa.’pa.toh] en San Juan, y con el mantenimiento [sa.’pa.tos] en la Ciudad de México (Morgan, 2010).
En esta investigación, me voy a enfocar en la pronunciación de los tejanos de origen mexicano. Se cree que existe influencia del inglés en el español de los hispanohablantes tejanos, especialmente con la diferencia entre la pronunciación de las letras “s” y “z” en las dos lenguas.
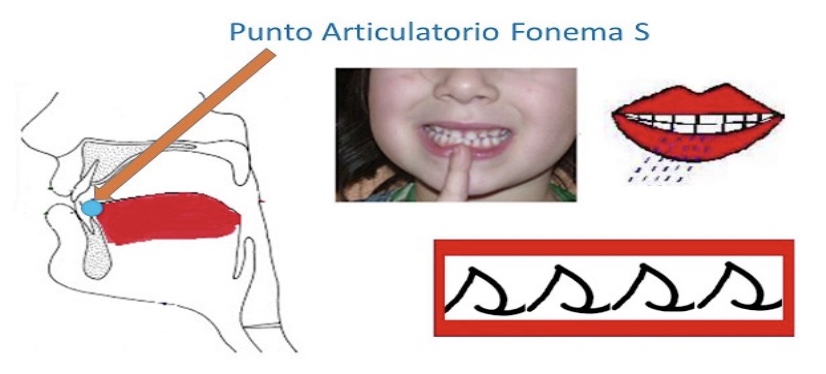
En general, /s/ y /z/ se describe como consonantes fricativas y alveolares. Se consideran fricativas porque se producen por una obstrucción parcial de aire (Figueroa Mathey, 2021; Morgan, 2010). Con respecto al lugar de articulación, la lengua se acerca a los alvéolos, ubicados en la parte superior de la boca, detrás de los dientes, representados por el número 3 en la Figura 1 de abajo (Morgan, 2010).
La diferencia principal entre estos sonidos se explica por la vibración en las cuerdas vocales. Hay dos tipos de sonidos:
- Un sonido sordo ocurre cuando no hay vibración en las cuerdas vocales.
- Un sonido sonoro se produce con vibración.
Se puede confirmar si un sonido es sonoro por colocarse una mano en la parte superior del cuello y sentir la vibración de las cuerdas (Morgan, 2010).
En español, el sonido /s/ se mantiene sorda en posición de ataque, o inicio de sílaba. En posición de coda, o final de sílaba, la /s/ puede asimilarse en sonoridad y realizarse como la sonora [z] cuando le sigue una consonante sonora como /b/, /m/, /l/, entre otras. Por ejemplo, “mismo” se pronuncia [‘miz.mo]; “desde” se pronuncia [‘dez.ðe] y “isla” se pronuncia [‘iz.la]. En los demás contextos /s/ se mantiene la realización sorda [s] como “rasco”, que se pronuncia [‘ras.ko] (Morgan, 2010).
En el inglés americano, la diferencia entre las letras “s” y “z” representa una distinción fonémica clara: /s/ y /z/ son dos sonidos distintos que pueden cambiar el significado de una palabra. Por ejemplo, “sip” vs. “zip”, y “bus” vs. “buzz”. La sonoridad producido es tan estable en inglés que incluso cuando la letra “s” aparece al final de palabras como “dogs” y “beds”, se pronuncia como [z]. Así, para los angloparlantes, alternar entre [s] y [z] es no solo común, sino necesario para hablar correctamente (Figueroa Mathey, 2021; Morgan, 2010).
En español mexicano, no existe una diferencia fonémica entre/s/ y /z/. Más bien, todas las letras “s”, “z”, y “c” (ante “e” o “i”) representan el mismo fonema /s/. Por eso, palabras como “cena”, “silla”, y “zapato” comienzan con el mismo sonido, a diferencia del inglés. La única excepción aparece en posición de coda, cuando /s/ está seguido por una consonante sonora, como en “mismo” [‘miz.mo], donde se produce una asimilación natural que convierte la /s/ sorda a la [z] sonora. Sin embargo, esta sonorización no cambia el significado y no se percibe como un sonido distinto (Morgan, 2010).
Los Participantes
Roel Alemán es un hombre de 59 años, cuya primera lengua fue el español, ya que es mexicanoamericano de tercera generación (sus dos abuelas nacieron en el norte de México). Sus padres conocían el ingles pero no lo hablaban con fluidez, por lo que Roel no aprendió el inglés hasta el primer grado, y ahora lo utiliza principalmente en su vida cotidiana. Llegó a obtener una licenciatura en administración de empresas. Es del Valle del Río Grande, como también lo es la próxima participante.
La segunda participante es Andrea García, de la misma familia mexicanoamericana como Roel. Andrea es una mujer de 24 años cuya primera lengua fue el inglés. Comenzó a aprender el español alrededor de los ocho años. En su hogar se habla una mezcla de español e inglés, pero predomina el inglés en su vida diaria. Su abuela paterna nació en Monterrey, por lo que ella también es mexicanoamericana de la tercera generación. Su grado más alto de estudios es una licenciatura en educación.
Se les pidió a Roel y a Andrea que participaran en este estudio por su estatus de mexicanoamericano. A ambos se les pidió leer tres pequeños párrafos del libro Alicia en el País de las Maravillas (Carroll, 2016). Este libro se eligió debido a su redacción compleja, para que funcionara como pieza de distracción de los grafemas que representan el sonido /s/. Ambos participantes pudieron familiarizarse con los párrafos antes de grabar, para reducir los nervios, y cada grabación duró aproximadamente dos minutos y medio. No se les dio ninguna pista sobre el propósito de la investigación antes de completar las tareas requeridas.
Abajo están los párrafos completos que leyeron los participantes. Las palabras que están en negrita se pronuncian con [s], y ellos que son en letra cursiva se pronuncian con [z], según las normas típicas de la variedad del español hablado en México.
Párrafo 1: ¡No sé si estoy cayendo a través de la tierra! ¡Qué divertido sería salir por el otro lado, donde la gente anda de cabeza! Los “antipáticos”; creo que se llaman así. – Ahora se alegraba de que nadie la oyera, pues no le sonaba del todo apropiada esta palabra: – Pero claro, bien tendré que preguntarles el nombre de su país. ¿Tiene usted la bondad, señora, de decirme si esto es Nueva Zelanda o Australia?
Párrafo 2: Lo mismo que un pueblo que ha encontrado rey. En efecto, Alicia sentía la superioridad de la inteligencia, y los animalitos aguzaban su instinto, estimulando al entusiasmo sólo por la mirada de la niña, donde brillaba la luz de la razón. Sin embargo, cada cual conservaba su carácter y su instinto, y en pasando el alborozo de la ovación, todos volvieron a componer, ya sus plumas, ya su pelambre, para recobrar la compostura y la gravedad propia de un pueblo sumiso.
Párrafo 3: ¡Ah, ahora caigo! – exclamó Alicia, que no había prestado atención a las palabras de la Duquesa. – La mostaza es un producto vegetal, aunque no lo parezca.
La revision auditiva no es una medida suficientemente exacta para validar las pronunciaciones. Así que se usó la herramienta Praat (Boersma & Weenink, 2025) para identificar los sonidos producidos por los hablantes. Sin embargo, no se pudo analizar 100% de las pronunciaciones de /s/, debido a ruidos de fondo o errores cometidos por los hablantes.
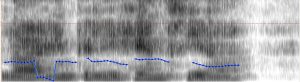
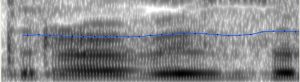
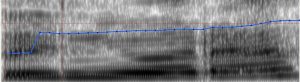
A continuación, se muestran algunas imágenes de las espectrografías de Praat. El foco principal estaba en la presencia o la ausencia de la línea azul. Esta línea indica un sonido sonoro, en que vibran las cuerdas vocales, mientras que la ausencia de la línea indica un sonido sordo, sin vibración de las cuerdas vocales.
Imágenes de Roel:
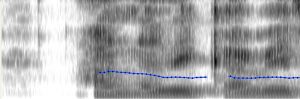
Imágenes de Andrea:
A partir de este análisis en profundidad, descubrí que Roel hablaba con más confianza mientras Andrea tropezaba, aunque no tanto con las palabras de la tarea, más bien con las distracciones. Solo con escuchar la grabación, hubo problemas para indicar las ligeras diferencias de vibraciones y así confirmar con precisión los sonidos producidos.
Praat pudo detectar que Roel tenía dificultades para emitir “través” y “pues” en el primer párrafo, que pronunció como [s]; sin embargo, se suponía que debía producir la sonora [z], por las consonantes sonoras (/d/ y /n/) que les siguen. Supongo que, debido a su rato despacio al hablar, pudo haber influido en pronunciar las palabras por separado con una pausa, contribuyendo a la sorda [s].
Praat también pudo detectar que Andrea produjo la sonora [z] para las palabras “cabeza”, “sonaba” y “preguntarles”. Aunque estas palabras deben pronunciarse con la sorda [s], debido a que la /s/ se usa como ataque, o es una coda a que no sigue una consonante sonora. Sin embargo, no está claro si existen otros errores en las palabras “aguzaban”, “razón”, “conservaba”, “pasando” y “alborozo”, debido al posicionamiento de la línea azul.
En conclusión, por los espectrogramas que muestran la producción fonética, se puede observar que la edad es un factor que afecta el habla de los dos participantes. Su experiencia acumulada de usar la lengua puede haber influido significativamente en la precisión articulatoria. Roel, por haber tenido más años de exposición al español y un contacto más temprano con la lengua, demuestra un mayor grado de automatización en su pronunciación, aunque incluso él presenta caso de ensordecimiento no esperado, especialmente cuando habla despacio. Esto confirma que la velocidad del habla y las pauses entre palabras también pueden alterar la pronunciación natural de los alófonos de /s/, incluso en hablantes con dominio sólido del español.
Andrea, por otro lado, refleja un patrón típico de muchos hablantes mexicanoamericanos cuya lengua dominante es el inglés: una tendencia a sonorizar /s/ en contextos donde el español mexicano no lo hace, así como fluctuaciones debidas al procesamiento simultáneo de lectura y pronunciación. Esto sugiere que la transferencia fonológica del inglés, donde la distinción /s/–/z/ es fonémica y altamente estable, influye en su producción del español, particularmente en ataques silábicos, donde el español no permite [z] como variante regular. Además, el nivel de fluidez lectora parece jugar un papel clave: la vacilación, la autocorrección y las pausas incrementan la probabilidad de realizar sonidos fuera de su contexto esperado.
Los resultados también muestran grabaciones caseras y la presencia de ruido ambiental, lo cual complicó la interpretación precisa de algunos espectrogramas. Sin embargo, incluso dentro de estas limitaciones, los patrones generales apoyan la hipótesis de una interacción entre el inglés y el español en hablantes bilingües tejano-mexicanos, en que factores como la edad, el dominio de cada lengua, la frecuencia de uso y el contexto comunicativo influyen en la producción fonética.
Este estudio aporta evidencia de que la variación en la pronunciación de las letras “s” y “z” no es únicamente un fenómeno lingüístico, sino también sociolingüístico: refleja la identidad, la historia familiar, la experiencia educativa y el entorno lingüístico de cada hablante.
Referencias
Boersma, P., & Weenink, D. (2025). Praat: Doing phonetics by computer. https://praat.org
Carroll, L. (2016). Alicia en el país de las maravillas (M. Sanz Jiménez, Trans.). Universidad Complutense de Madrid. (Original work published 1865). https://produccioncientifica.ucm.es/documentos/63be0eefa99efc1c4808eea0
Escuela Pablo Neruda San Miguel. (2020). Cápsula PIE /1º básico/punto articulatorio: consonante s/ fonoaudióloga. [Video]. YouTube. https://youtu.be/FbdAnfNcRo8?si=DWxwsvBPVf0jVR6s
Figueroa Mathey, E. (2021). Diseño de una unidad didáctica para la enseñanza de la pronunciación de los sonidos /ʒ/, /s/ y /z/ [Master’s thesis, Universidad Nacional Autónoma de México]. Repositorio UNAM. https://ru.dgb.unam.mx/server/api/core/bitstreams/7a966283-3623-4fea-9635-3c033c8618e4/content
Moslimani, M., Noé-Bustamante, L., & Shah, S. (2023, August 16). Facts on Hispanics of Mexican origin in the United States, 2021. Pew Research Center. https://www.pewresearch.org/race-and-ethnicity/fact-sheet/us-hispanics-facts-on-mexican-origin-latinos/
Morgan, T. A. (2010). Sonidos en contexto: Una introducción a la fonética del español con especial referencia a la vida real. Yale University Press.

